私が所属している Web フロントエンドチームでは、UI コンポーネントや画面の差分検知を行う Visual Regression Testing(以下、VRT)を 4 年以上にわたって導入しています。それを実際に運用する中でいくつかの課題を発見・解決してきました。本記事は、VRT がよりテストとして機能するための取り組みを紹介します。
Visual Regression Testing で得られる恩恵と課題
前置き
前提として、Web フロントエンドにおける VRT の手法として Playwright を使った差分検知や、BrowserStack などが挙げられますが、私が所属しているチームでは Storybook で表示した story 群に対して reg-viz/storycap と reg-viz/reg-suit を使ったテストを GitHub Actions 上で実践しています。
そのため本記事で紹介する事例は、全てのツール・手法に共通するものではありません。また、どの環境でも汎用的に適用できるとは限りません。あらかじめご注意下さい。
また、storycap を並列処理で走らせることによる高速化であったり、事前に必要なビルド時間を短縮するような既存のソリューションに関してはこの記事では説明しません。それらに関しては下記記事がとてもわかりやすく説明してくださっていますので、必要に応じて参考ください。
 wadackel.mereg-suit と storycap で行う Visual Regression Testing の高速化過去このブログでは Visual Regression Testing(以降 VRT)に関連した記事をいくつか書いてきました。 Puppeteer を使った Storybook の自動スクリーンショッ…
wadackel.mereg-suit と storycap で行う Visual Regression Testing の高速化過去このブログでは Visual Regression Testing(以降 VRT)に関連した記事をいくつか書いてきました。 Puppeteer を使った Storybook の自動スクリーンショッ…
 zenn.devVRTの実行時間を短縮した話
zenn.devVRTの実行時間を短縮した話
恩恵と課題
VRT による恩恵はいくつかありますが、中でも、意図しない visual の差分検知を開発者に伝えることができる点が非常に有用です。
例えば、UI コンポーネントのリファクタリングを行う際に VRT で差分検知が発生した場合にはそれを指摘するコミュニケーションが行えていて、実際に品質向上の手がかりとして機能していると感じます。しかしながら、当初は成り立っていた機能が肥大化するに伴っていくつかの課題が発生していきました。
実行時間が長い
まず 1 点目は VRT の実行時間が長いことです。弊チームではテストの対象数が一時期 25,000 程度で、実行時間が 30 分を超えることも珍しくありませんでした。
.png)
25,000 の内訳としては、story(1,250)× theme(5)1× viewport(4)を Pull Request 毎に実行しており、副次的に Billing Time も懸念していました。
VRT のレポートを見なくなる
テストの実行時間が長いことによって別の課題も発生しました。それは VRT のレポートが見られにくくなるという課題です。例えば、
- レポートが生成されていないので Pull Request をコードだけ見てレビュー
- 急ぎの Pull Request なので、レポートの生成を待たずにマージ
など、開発の優先度と実行時間のバランスが取れず、運用されなくなる傾向がありました。
「差分なし」のセマンティクスが薄くなる
約 25,000 も差分検知を行っていると、その結果の解釈にも影響があります。例えば下記添付画像は、とあるコンポーネントのスタイルを変更したレポートです。内容を見てみると
- 変更した内容を踏まえて 4 items に対して差分が発生していること
- 変更した内容を踏まえて 24,724 items には差分が発生していないこと
が理解できるでしょう。
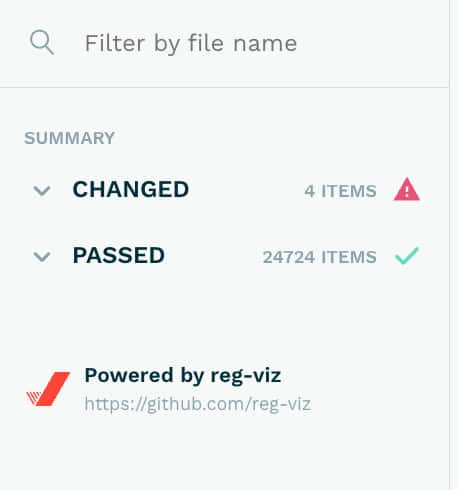
しかしながら、2 は以下が混在した結果です。
- 「変更の影響を受けた上で差分検知がなかったもの」
- 「そもそも変更に影響しなかったもの」
そのため、Pull Request が影響する範囲で、本当に差分が発生しなかった結果を認識することができなくなります。従って、VRT をより活用するためには「差分なし」(reg-viz でいうところの PASSED)の内容も毎回確認することが重要だと考えています。2
より活用するために
いくつかの課題によって、VRT が運用されなくなる環境・文化になっていきました。その弊害として、UI が少しだけデグレードするなどの些細なバグを起こすようになったため改善を進めることになりました。
さて、より VRT を活用するためには何を改善すれば良いのでしょうか?
結論から述べると、Pull Request の変更に関連した内容のみを VRT の対象とすることで、大きく実行時間を短縮・高速化させることが有効だと考えています。そして、素早く・効率的に VRT をチームへ浸透させるこ�とが可能だと考えています。
.png)
私が所属しているチームでは次項で説明するテクニックを導入することで 30 分必要とした実行時間が 3 分 ~ 6 分までに短縮することができました。その結果、よりチームがレポートを見るようになり VRT が以前よりも運用されているように感じます。
.png)
Pull Request の影響範囲のみを VRT の対象とする
前述の通り、VRT を効率よくスピーディーに運用していくためには、「Pull Request の変更内容に関連した内容のみを VRT で検知・検査」することが効果的です。
まず前提として、私のチームでは元々以下のようなフローで VRT のレポート生成を行っていました。
- Pull Request のマージ先・マージ元ブランチでそれぞれ
storybook buildを実施してstorybook-staticの生成 - それぞれの storybook-static を元に storycap を実施してスクリーンショットの生成
- reg-suit を実施して VRT のレポート生成
このフローに対して「Pull Request の変更内容に関連した内容のみを VRT で検知・検査」するには、以下のように処理を変更することで実現可能です。
- Pull Request のマージ先・マージ元ブランチでそれぞれ
storybook buildを実施してstorybook-staticの生成 - 生成された
storybook-staticを比較して差分が発生したもののみをピックアップ - それぞれの storybook-static を元に storycap を実施して、2 で差分が発生しているものだけに関してスクリーンショットの生成
- reg-suit を実施して VRT のレポート生成
このようにフローを変更することで膨大な story 群全てに対して storycap を実施する必要がなくなり、レポート生成までの時間を大幅に短縮することが可能で、実際に 1 ~ 3 のフローの中で一番実行時間が長くクリティカルパスとして致��命的だったボトルネックを改善することができました。
.png)
次項では、具体的にどのようにして Pull Request の差分を検知したのかを説明します。
storybook-static の比較
storybook build を実行して生成される storybook-static は以下のようなディレクトリで構成されています。
storybook-static├── 17626.0ad84914.iframe.bundle.js├── 25984.c84e0ac1.iframe.bundle.js├── component1.123456.iframe.bundle.js├── component2.123457.iframe.bundle.js├── component3.123458.iframe.bundle.js├── favicon.svg├── iframe.html├── index.html├── index.json├── main.8f1994dc.iframe.bundle.js├── project.json├── runtime~main.e792fcf9.iframe.bundle.js└── static
注目したいのが、component1.123456.iframe.bundle.js のような chunk です。これらは story コンポーネント単位で chunk が生成されており、これらの hash を比較することで変更の影響を確認することが可能です。3
ただし、これはバンドラーによって生成された chunk であるため、ヘッダーやフッターなどの共通コンポーネントはバンドラーの設定に応じて共通化された状態で生成され、story コンポーネントなどはそれぞれ独立された状態でバンドルされる(はず)です。4
つまり、story コンポーネントが複数個の chunk file をネストして呼び出す構造になっているため、story コンポーネントに差分が発生しているかどうかを調べるには、chunk file の中身を解析し�て依存関係を把握した上でそれら全てを検査・比較する必要があります。
そのようなロジックを組むのは実行コストが高いと考えているため、VRT を実行する時の Storybook のビルドには バンドラーの設定で chunk splitting を無効化して 1 つの story コンポーネントに対して完全な 1 つの .js を生成する ことを推奨します。5
下記はその例ですが、私のチームは依然として webpack を利用しているため、任意のバンドラーのコードに置き換えていただけると幸いです。
export default {// 省略optimization: {splitChunks: false, // story 単位での hash 算出をしやすくするために、splitChunks を無効化},};
この設定を行うことで、entry ファイルである story コンポーネントに対して 1 つの完全な .js が生成されるようになります。この状態で story コンポーネントの hash を比較することで差分の検知が簡単に行えるようになります。もし バンドル時間の増加・チャンクサイズの増加などが懸念される方は依存関係の解決をスマートに行えればそちらでも代替可能かと思われます。
次にこの設定を行った上で、以下のような script を実行すると生成した story コンポーネントとその hash をまとめた json が生成されますので、VRT のタイミングで変更前・後の json 同士を比較すると影響した story が識別できるようになります。
const keyAndHashRegexp = /(.*)-([a-z0-9]+)\.iframe\.bundle\.js$/;function getStoryKeyAndHash(filename: string): [string | undefined, string | undefined] {const match = filename.toLowerCase().match(keyAndHashRegexp);if (match && match.length === 3) {return [match[1], match[2]];}return [undefined, undefined];}async function main() {const dir = process.argv[2];if (!dir) {console.error("Usage: node --experimental-strip-types generate-hash.ts <directory>");process.exit(1);}const hashMapping: Record<string, string> = {};try {const items = await fs.promises.readdir(dir);for (const item of items) {if (item.endsWith(".iframe.bundle.js")) {const [key, hash] = getStoryKeyAndHash(item);if (key && hash) {hashMapping[key] = hash;}}}} catch (error) {console.error(`Error reading directory: ${dir}`, error);process.exit(1);}const outputJson = JSON.stringify(hashMapping, null, 2);console.info(outputJson);}main().catch(console.error);
そして、生成した hash を元に変更のあった story コンポーネントのみを列挙し、VRT の対象として処理を進めていきます。簡単な例として以下を参考にしていただければ幸いです。
const getAllStories = async (rootPath: string): Promise<string[]> => {const storiesJsonPath = resolve(rootPath, "storybook-static/index.json");const prevHashPath = resolve(rootPath, "storybook-hash-prev.json");const nextHashPath = resolve(rootPath, "storybook-hash-next.json");try {const [prevHashRaw, nextHashRaw, storiesRaw] = await Promise.all([fs.readFile(prevHashPath, "utf-8"),fs.readFile(nextHashPath, "utf-8"),fs.readFile(storiesJsonPath, "utf-8"),]);const prevHash: Record<string, string> = JSON.parse(prevHashRaw);const nextHash: Record<string, string> = JSON.parse(nextHashRaw);const stories: { entries: Record<string, { title: string }> } =JSON.parse(storiesRaw);const changes = Object.entries(nextHash).reduce<string[]>((acc, [key, value]) => {if (prevHash[key] !== value) {acc.push(key);}return acc;},[]);console.info("Changed stories: ", changes);const titles = Object.entries(stories.entries).filter(([key]) => changes.some((c) => key.includes(c))).map(([, { title }]) => `${title}/**`);console.info("Target stories: ", titles);return uniq(titles);} catch (error) {console.error("Error reading or parsing JSON files:", error);return [];}};
実現するにあたっての注意点
ただし、これを実現するにはアプリケーションの実装にいくつかの制約・注意点が発生します。
可能な限り Tree Shaking すること
前述した chunk や hash をベースとした比較には、tree shaking によってその .js ファイルが適切な関心のみを扱っていることが前提となります。
仮に tree shaking できていないモジュールが存在すると、直接的に影響していない story コンポーネントにも影響が及びます。
この影響によって、余分なスクリーンショットの作成やレポート生成までの実行時間が長くなったり、レポートの精度が下がることに直結するため、極力 tree shaking を意識しましょう。
私のチームでは多言語化対応を行っており、その文字情報を全て json で管理していた影響でこの差分検知に苦戦しました(最終的に自前の i18n 戦略に乗り換えることで tree shaking 対応を行いました)。
副作用を持つ処理を排除する
Storybook で生成された JavaScript ファイルのみを見た差分検知手法であるため、Storybook 上で実際にコンポーネントをマウントしてから通信処理が始まるコンポーネントとの相性は悪い場合があります。例えば、MSW を用いた通信処理でモックデータをコンポーネントに渡す場合、 hash の比較だけでは差分を正確に検知できないことがあります。
対照的に、Container/Presenter パターン等を用いてコンポーネントの副作用を明確に切り出しているコンポーネントとの親和性は特に良いでしょう。
opt-in で全ての story コンポーネントを検査できるようにしておく
例えば外部依存ライブラリのバージョンアップ Pull Request などでは、story コンポーネントに影響が発生しているにも関わらず、 hash が変わらないケースが存在し得ます。
そのようなケースを想定し、特定の操作で全ての story コンポーネントを比較対象とするようなオプションの仕組みを備えておくと柔軟に対応できます。
例えば私のチームでは、Commit Message に vrt-all という文字を含めることで全ての story コンポーネントを比較対象とすることが可能になっています。
その他の高速化手法
他にも私のチームでは以下を導入しており、これらの組み合わせで VRT 実行時間を 3 ~ 6 分ほどに短縮することができました。これらの説明に関しては他のブログが参考になるかと思われますので、本記事での説明は省略します。
まとめ
VRT の運用について、高速化するテクニックを紹介しました。
これらの取り組みによって、以前は 30 分以上かかっていた VRT が、今では 6 分以内で完了することも珍しくありません。さらに、story コンポーネントに影響しない変更を加えた場合は hash の差分検知のみで VRT の処理が完了するため、3 分程度で全ての処理が完了することもあります。
その結果、チーム内でレポートがより確認されるようになり、VRT が以前よりもずっと身近な存在になったと感じています。この経験が、これから VRT に取り組む方々にとって少しでもお役に立てれば幸いです。
疑問点やご指摘等ございましたら、気軽に @kqito までご連絡ください(レスポンスが遅れることが多々あります)。